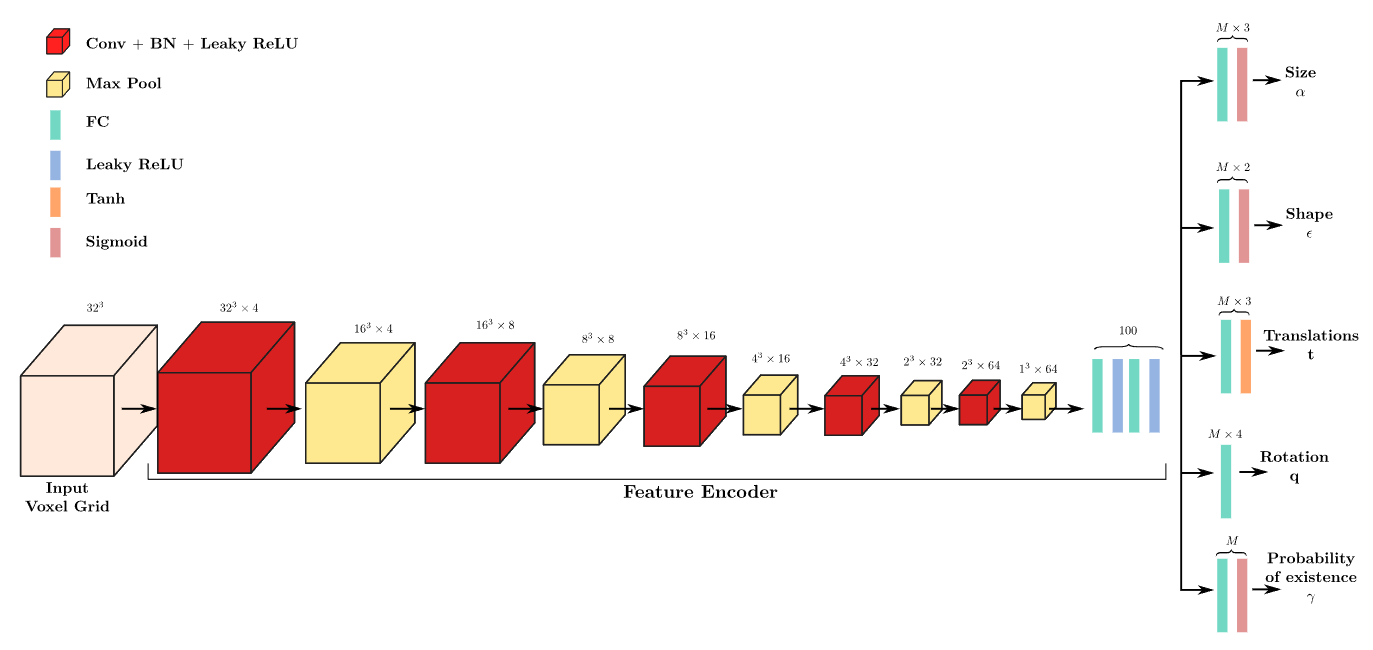
以下是完整的可长按鼠标右键控制旋转的常见FPS相机完整代码
Main.cpp
#include <glad/glad.h>
#include <GLFW/glfw3.h>
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>
#include <glm/gtc/type_ptr.hpp>
#include <iostream>
#include <fstream>
#include <thread>
#include <chrono>
#include "shader.h"
#include "texture.h"
#include "camera.h"
using std::cout;
using std::endl;
void framebuffer_size_callback(GLFWwindow* window, int width, int height);
void processInput(GLFWwindow* window, int rateLocation, float rate, Camera *camera);
void mouseCallBack(GLFWwindow* window, double xpos, double ypos);
void scrollCallBack(GLFWwindow* window, double xoffset, double yoffset);
//硬编码的顶点着色器 包括位置旋转等操作
const char* vertexShaderSource = "./shaders/VertexShader.glsl";
//硬编码的片段着色器 主要是渲染颜色
const char* fragmentShaderSource = "./shaders/FragmentShader.glsl";
// settings
const unsigned int SCR_WIDTH = 800;
const unsigned int SCR_HEIGHT = 600;
float deltaTime = 0.0f; // 当前帧与上一帧的时间差
float lastFrame = 0.0f; // 上一帧的时间
int main()
{
// glfw: initialize and configure
// ------------------------------
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 4);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 6);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
#ifdef __APPLE__
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE);
#endif
// glfw window creation
// --------------------
GLFWwindow* window = glfwCreateWindow(SCR_WIDTH, SCR_HEIGHT, "LearnOpenGL", NULL, NULL);
if (window == NULL)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
// glad: load all OpenGL function pointers
// ---------------------------------------
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress))
{
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
// ready for render
float vertices[] = {
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
0.5f, -0.5f, -0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 1.0f,
0.5f, 0.5f, 0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, 0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, -0.5f, 1.0f, 1.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f
};
glm::vec3 cubePositions[] = {
glm::vec3(0.0f, 0.0f, 0.0f),
glm::vec3(2.0f, 5.0f, -15.0f),
glm::vec3(-1.5f, -2.2f, -2.5f),
glm::vec3(-3.8f, -2.0f, -12.3f),
glm::vec3(2.4f, -0.4f, -3.5f),
glm::vec3(-1.7f, 3.0f, -7.5f),
glm::vec3(1.3f, -2.0f, -2.5f),
glm::vec3(1.5f, 2.0f, -2.5f),
glm::vec3(1.5f, 0.2f, -1.5f),
glm::vec3(-1.3f, 1.0f, -1.5f)
};
//定义并生成一个VAO 存储VBO的链表结构
unsigned int VAO;
glGenVertexArrays(1, &VAO);
//绑定VAO
glBindVertexArray(VAO);
// 定义并生成一个顶点缓冲对象 通过无符号整数引用
unsigned int VBO;
glGenBuffers(1, &VBO);
// 绑定新生成的顶点缓冲对象
glBindBuffer(GL_ARRAY_BUFFER, VBO);
// 顶点数据复制到缓冲中
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// 编辑顶点属性
// 1. 设置顶点属性指针
//链接顶点属性 (向顶点着色器指定输入
// 1、顶点着色器中定义的location
// 2、顶点缓冲的长度
// 3、顶点数据的类型
// 4、数据是否标准化(即映射到标准化设备坐标中)
// 5、连续顶点属性组之间的间隔
// 6、初始顶点在缓冲中距离地址最开始的偏移量
// 0. 复制顶点数组到缓冲中供OpenGL使用
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)(3* sizeof(float)));
glEnableVertexAttribArray(1);
Shader shader = Shader(vertexShaderSource, fragmentShaderSource);
Texture texture1 = Texture("123.png", GL_RGB);
Texture texture2 = Texture("awesomeface.png",GL_RGBA);
shader.use();
shader.setInt("ourTexture", 0);
shader.setInt("secondTexture", 1);
// 定义第二个图片的初始透明度
int rateLocation = glGetUniformLocation(shader.ID, "rate");
glUniform1f(rateLocation, 0.2f);
// 定义初始的位移矩阵为单位矩阵
glm::mat4 trans = glm::mat4(1.0f);
int transLocation = glGetUniformLocation(shader.ID, "transform");
glUniformMatrix4fv(transLocation, 1, GL_FALSE, glm::value_ptr(trans));
//相机作为观察矩阵 不每次初始化
Camera camera(glm::vec3(0.0f, 0.0f, 3.0f));
// render loop
// -----------
while (!glfwWindowShouldClose(window))
{
//计算设备每一帧渲染的时间,乘以速度获取更流畅的动画
float currentFrame = glfwGetTime();
deltaTime = currentFrame - lastFrame;
lastFrame = currentFrame;
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
//Z缓冲 保证透视正常
glEnable(GL_DEPTH_TEST);
// input
// -----
float ratevalue;
glGetUniformfv(shader.ID, rateLocation, &ratevalue);
float transMatrix[16];
glGetUniformfv(shader.ID, transLocation, transMatrix);
processInput(window, rateLocation, ratevalue, &camera);
glfwSetWindowUserPointer(window, &camera);
glfwSetCursorPosCallback(window, mouseCallBack);
glfwSetScrollCallback(window, scrollCallBack);
shader.setMat4("view", camera.GetViewMatrix());
glm::mat4 projection = glm::perspective(glm::radians(camera.Zoom), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 100.0f);
shader.setMat4("projection", projection);
// render a verticle
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texture1.ID);
glActiveTexture(GL_TEXTURE1);
glBindTexture(GL_TEXTURE_2D, texture2.ID);
glBindVertexArray(VAO);
for (unsigned int i = 0; i < 10; i++)
{
glm::mat4 model = glm::mat4(1.0f);
model = glm::translate(model, cubePositions[i]);
float angle = 20.0f * (i + 1);
model = glm::rotate(model, (float)glfwGetTime()*glm::radians(angle), glm::vec3(1.0f, 0.3f, 0.5f));
shader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 36);
}
// opengl绘制图元方式
/*glPolygonMode(GL_FRONT_AND_BACK, GL_LINE);*/
// glfw: swap buffers and poll IO events (keys pressed/released, mouse moved etc.)
// -------------------------------------------------------------------------------
glfwSwapBuffers(window);
glfwPollEvents();
}
// glfw: terminate, clearing all previously allocated GLFW resources.
// ------------------------------------------------------------------
glfwTerminate();
return 0;
}
// process all input: query GLFW whether relevant keys are pressed/released this frame and react accordingly
// ---------------------------------------------------------------------------------------------------------
void processInput(GLFWwindow* window,int rateLocation, float rate, Camera *camera)
{
float cameraSpeed = 1.0f * deltaTime;
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
else if (glfwGetKey(window, GLFW_KEY_W) == GLFW_PRESS) {
rate = rate + 0.1 > 1.0 ? 1.0 : rate + 0.1;
camera->ProcessKeyboard(FORWARD, deltaTime);
glUniform1f(rateLocation, rate);
}
else if (glfwGetKey(window, GLFW_KEY_S) == GLFW_PRESS) {
camera->ProcessKeyboard(BACKWARD, deltaTime);
glUniform1f(rateLocation, rate - 0.1);
}
else if (glfwGetKey(window, GLFW_KEY_A) == GLFW_PRESS) {
camera->ProcessKeyboard(LEFT, deltaTime);
rate = rate - 0.1 < 0.0 ? 0.0 : rate - 0.1;
glUniform1f(rateLocation, rate - 0.1);
}
else if (glfwGetKey(window, GLFW_KEY_D) == GLFW_PRESS) {
camera->ProcessKeyboard(RIGHT, deltaTime);
rate = rate - 0.1 < 0.0 ? 0.0 : rate - 0.1;
glUniform1f(rateLocation, rate - 0.1);
}
}
bool firstMouse = true;
bool rightMouseDown = false;
float lastx = 400;
float lasty = 300;
void mouseCallBack(GLFWwindow* window, double xpos, double ypos)
{
Camera* camera = (Camera*)glfwGetWindowUserPointer(window);
if (firstMouse)
{
lastx = xpos;
lasty = ypos;
firstMouse = false;
}
if (rightMouseDown) {
float xoffset = xpos - lastx;
float yoffset = lasty - ypos;
lastx = xpos;
lasty = ypos;
float sensitivity = 0.05f;
xoffset *= sensitivity;
yoffset *= sensitivity;
camera->ProcessMouseMovement(xoffset, yoffset);
}
if (glfwGetMouseButton(window, GLFW_MOUSE_BUTTON_RIGHT) == GLFW_PRESS) {
rightMouseDown = true;
lastx = xpos;
lasty = ypos;
}
if (glfwGetMouseButton(window, GLFW_MOUSE_BUTTON_RIGHT) == GLFW_RELEASE) {
rightMouseDown = false;
}
}
void scrollCallBack(GLFWwindow* window, double xoffset, double yoffset)
{
Camera* camera = (Camera*)glfwGetWindowUserPointer(window);
camera->ProcessMouseScroll(static_cast<float>(yoffset));
}
// glfw: whenever the window size changed (by OS or user resize) this callback function executes
// ---------------------------------------------------------------------------------------------
void framebuffer_size_callback(GLFWwindow* window, int width, int height)
{
// make sure the viewport matches the new window dimensions; note that width and
// height will be significantly larger than specified on retina displays.
glViewport(0, 0, width, height);
}
Camera.h
#ifndef CAMERA_H
#define CAMERA_H
#include <glad/glad.h>
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>
enum Camera_Movement {
FORWARD,
BACKWARD,
LEFT,
RIGHT
};
const float YAW = -90.0f;
const float PITCH = 0.0f;
const float SPEED = 2.5f;
const float SENSITIVITY = 0.5f;
const float ZOOM = 45.0f;
class Camera
{
public:
// camera Attributes
glm::vec3 Position;
glm::vec3 Front;
glm::vec3 Up;
glm::vec3 Right;
glm::vec3 WorldUp;
// euler Angles
float Yaw;
float Pitch;
// camera options
float MovementSpeed;
float MouseSensitivity;
float Zoom;
// constructor with vectors
Camera(glm::vec3 position = glm::vec3(0.0f, 0.0f, 0.0f), glm::vec3 up = glm::vec3(0.0f, 1.0f, 0.0f), float yaw = YAW, float pitch = PITCH) : Front(glm::vec3(0.0f, 0.0f, -1.0f)), MovementSpeed(SPEED), MouseSensitivity(SENSITIVITY), Zoom(ZOOM)
{
Position = position;
WorldUp = up;
Yaw = yaw;
Pitch = pitch;
updateCameraVectors();
}
// constructor with scalar values
Camera(float posX, float posY, float posZ, float upX, float upY, float upZ, float yaw, float pitch) : Front(glm::vec3(0.0f, 0.0f, -1.0f)), MovementSpeed(SPEED), MouseSensitivity(SENSITIVITY), Zoom(ZOOM)
{
Position = glm::vec3(posX, posY, posZ);
WorldUp = glm::vec3(upX, upY, upZ);
Yaw = yaw;
Pitch = pitch;
updateCameraVectors();
}
// returns the view matrix calculated using Euler Angles and the LookAt Matrix
glm::mat4 GetViewMatrix()
{
return glm::lookAt(Position, Position + Front, Up);
}
// processes input received from any keyboard-like input system. Accepts input parameter in the form of camera defined ENUM (to abstract it from windowing systems)
void ProcessKeyboard(Camera_Movement direction, float deltaTime)
{
float velocity = MovementSpeed * deltaTime;
if (direction == FORWARD)
Position += Front * velocity;
if (direction == BACKWARD)
Position -= Front * velocity;
if (direction == LEFT)
Position -= Right * velocity;
if (direction == RIGHT)
Position += Right * velocity;
}
// processes input received from a mouse input system. Expects the offset value in both the x and y direction.
void ProcessMouseMovement(float xoffset, float yoffset, GLboolean constrainPitch = false)
{
xoffset *= MouseSensitivity;
yoffset *= MouseSensitivity;
Yaw += xoffset;
Pitch += yoffset;
// make sure that when pitch is out of bounds, screen doesn't get flipped
if (constrainPitch)
{
if (Pitch > 89.0f)
Pitch = 89.0f;
if (Pitch < -89.0f)
Pitch = -89.0f;
}
// update Front, Right and Up Vectors using the updated Euler angles
updateCameraVectors();
}
// processes input received from a mouse scroll-wheel event. Only requires input on the vertical wheel-axis
void ProcessMouseScroll(float yoffset)
{
Zoom -= (float)yoffset;
if (Zoom < 1.0f)
Zoom = 1.0f;
if (Zoom > 45.0f)
Zoom = 45.0f;
}
private:
// calculates the front vector from the Camera's (updated) Euler Angles
void updateCameraVectors()
{
// calculate the new Front vector
glm::vec3 front;
front.x = cos(glm::radians(Yaw)) * cos(glm::radians(Pitch));
front.y = sin(glm::radians(Pitch));
front.z = sin(glm::radians(Yaw)) * cos(glm::radians(Pitch));
Front = glm::normalize(front);
// also re-calculate the Right and Up vector
Right = glm::normalize(glm::cross(Front, WorldUp)); // normalize the vectors, because their length gets closer to 0 the more you look up or down which results in slower movement.
Up = glm::normalize(glm::cross(Right, Front));
}
};
#endif
VertexShader.glsl
#version 460 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoord;
out vec2 texCoord;
uniform mat4 transform;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main()
{
gl_Position = transform * projection * view * model * vec4(aPos, 1.0);
texCoord = aTexCoord;
}


 接口正常访问
接口正常访问